- 결측치(=값이 중간에 비어있음)가 존재하는지 확인
+ 데이터 분석을 할 때 결측치가 있으면 수식 작동이 안된다. > 확인하기
데이터를 불러온다.
import pandas as pd
df = pd.read_csv("data/Lemonade2016.csv")
이후 info()를 통해 결측치가 있는지 확인할 수 있다.
df.info()
# out :

>> Non-Null Count로 Null 값의 개수를 확인(Non-Null : Null이 아니다)
>> 위 예시에서는 전체 값이 32개이므로 31개의 non-null을 가진다면 결측치가 1개 있다는 뜻
결측치는 .dropna()로 삭제할 수 있다.
1) 행 기준으로 결측치 제거 : .dropna()
2) 열 기준으로 결측치 제거 : .dropna(axis=1)
3) 특정 열 기준으로 결측치 제거 : .dropna(subset=['특정 열'])
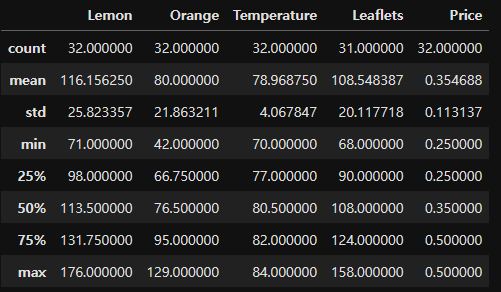
다음으로 describe()를 통해 수치 데이터를 확인할 수 있다.
df.describe() # 기술통계량 제공
# out :
문자열, 정수, 카테고리 값이 시리즈 값이라면 value_counts()를 통해 데이터를 확인할 수 있다.
각 종류별로 몇 개의 데이터가 있는지 세어준다.
df['Location'].value_counts()
# out :

- 컬럼 추가
먼저 원래 데이터를 확인한다.
df.head(10)
# out :

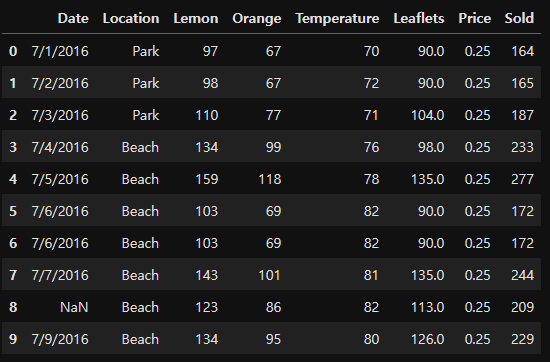
아래와 같이 'Sold'라는 컬럼을 추가한다.
df['Sold'] = 0 # df['컬럼명']
df.head(1)
# out :

>> 'Sold' 컬럼이 추가된 것을 확인할 수 있다.
컬럼에 데이터를 추가한다.
df['Sold'] = df['Lemon'] + df['Orange'] # sold에 lemon과 orange 합친 값 넣기
df.head(10)
# out :
>> Lemon과 Orange를 더한 값이 Sold에 출력된다.
- .drop.duplicates()를 통한 중복값 제거
위 데이터를 확인하면 7월 6일 자료가 두 개인 등 중복값이 있음을 알 수 있는데, 이를 제거할 수 있다.
매출액 컬럼을 추가하고 중복값을 제거하면 다음과 같다.
df['매출액'] = df['Sold'] * df['Price']
df = df.drop_duplicates(keep='first', ignore_index=True) # 중복값 지우기
df.head(10)
# out :

>> 중복값이 제거된 것을 확인할 수 있다.
- .drop()을 통한 행/열 제거
1) columns 제거 (axis=1)
df2 = df.drop('Sold', axis = 1) # drop('컬럼명', axis=1) : 컬럼이 지워짐
df2.head(5)
# out :

>> axis=1을 사용하면 특정 열을 지울 수 있다. 위에선 Sold 컬럼이 사라진 것을 볼 수 있다.
2) index 제거 (axis=0)
df3 = df.drop(3, axis=0) # drop(n, axis=0) : n번째 행이 지워진다.
df3.head(5)
# out :

>> 지정한 번호의 index가 제거된 것을 확인할 수 있다.(위에선 3)
- .loc[]를 이용한 행 추출
# 행 추출
# Location이 Beach인 것만 추출
# loc 사용, 모든 컬럼 조회
df.loc[df['Location'] == 'Beach', :]
- sort_values()를 이용한 데이터 정렬
1) 오름차순
df.sort_values(by = ['매출액']).head(5) # 기본값 오름차순
# out :

>> 매출액의 데이터가 오름차순으로 정렬되었다.
2) 내림차순
ascending=False을 통해 내림차순으로 변경할 수 있다.
df.sort_values(by = ['매출액'], ascending=False).head(5)
# out :
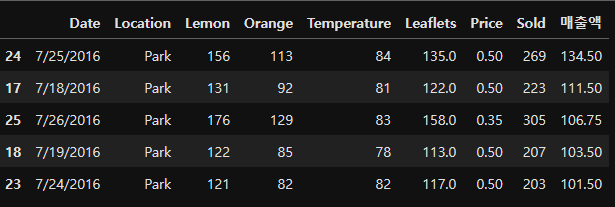
>> 매출액의 데이터가 내림차순으로 정렬되었다.
- Groupby 연산
* Groupby 기준컬럼 : 패턴이 있는 문자열
* Groupby 대상컬럼 : 수치 데이터
* 필요한 함수 : 집계함수(합, 평균, 표준편차, 최대, 최소 등)
* 형식 : df.groupby ('기준컬럼') ['대상컬럼'] .집계함수
df.groupby('Location')['매출액'].agg(['sum', 'mean', 'std'])
# out :

위 상태에서 reset_index()를 통해 집계함수를 열로 만들 수 있다.
df.groupby('Location')['매출액'].agg(['sum', 'mean', 'std']).reset_index()
# out :

'Python' 카테고리의 다른 글
| 가설검정 (t-검정/가설검정 오류/양측검정과 단측검정) (1) | 2024.01.11 |
|---|---|
| [plotly] 사용법 간단 정리 (0) | 2024.01.09 |
| [seaborn] 데이터 시각화(+matplotlib) (1) | 2024.01.08 |
| [pandas] 엑셀 파일 불러오기, 내보내기 (1) | 2024.01.08 |
| [pandas] 데이터 통합하기 (0) | 2024.01.08 |